Automated Patient Anonymisation and Data Masking Pipeline
Problem to Solve
Health and medical researchers are desperate to get their hands on NHS data for many reasons, the principal gem being its
longitudinal attributes. To date, privacy considerations have rightly been a barrier, as medical records and files are
heavily populated with sensitive Personally Identifiable Information (PII).
Moving this raw data into analytical environments creates severe security vulnerabilities, not to mention regulatory
nightmares. Manual redaction processes are completely unscalable, slow, and highly susceptible to human error.
Without a secure, automated, and real-time data masking infrastructure, healthcare providers are forced to choose
between stalling vital medical innovation or risking catastrophic compliance breaches, severe regulatory penalties,
and the exposure of sensitive patient identities.
A number of solutions have been proposed, and potentially one of the most effective is homomorphic encryption (HE).
While HE has successfully transitioned from a purely theoretical mathematical concept into highly polished enterprise
software, its widespread adoption is still limited by extreme computational overheads and structural limitations.
The solution proposed in this project would resolve the conflict between clinical data utilisation and strict patient
privacy mandates by expunging NHS data of PII while in transit to particular environments, thereby enabling much needed
research to be carried out in the meantime, until such a time that HE becomes mature enough and a mainstream
general-purpose technology.
This project implements and provisions an event-driven data engineering pipeline designed to resolve the conflict
between clinical data utilisation and strict patient privacy mandates. The pipeline automates the anonymisation of healthcare
data in transit, ensuring compliant datasets are available for immediate medical research while completely safeguarding
PII. This directly satisfies GDPR and Caldicott Principles.
Objective
Design, build, and deploy a production-grade, real-time streaming anonymisation pipeline that:
• Intercepts NHS patient records at ingestion.
• Applies configurable, field-aware anonymisation strategies - pseudonymisation and redaction.
• Delivers clean, research-ready records to downstream analytical storage.
• Maintains full GDPR and NHS DSP Toolkit compliance throughout.
• Is fully automated, observable, and infrastructure-as-code driven - deployable to AWS at scale.
Architecture Diagram
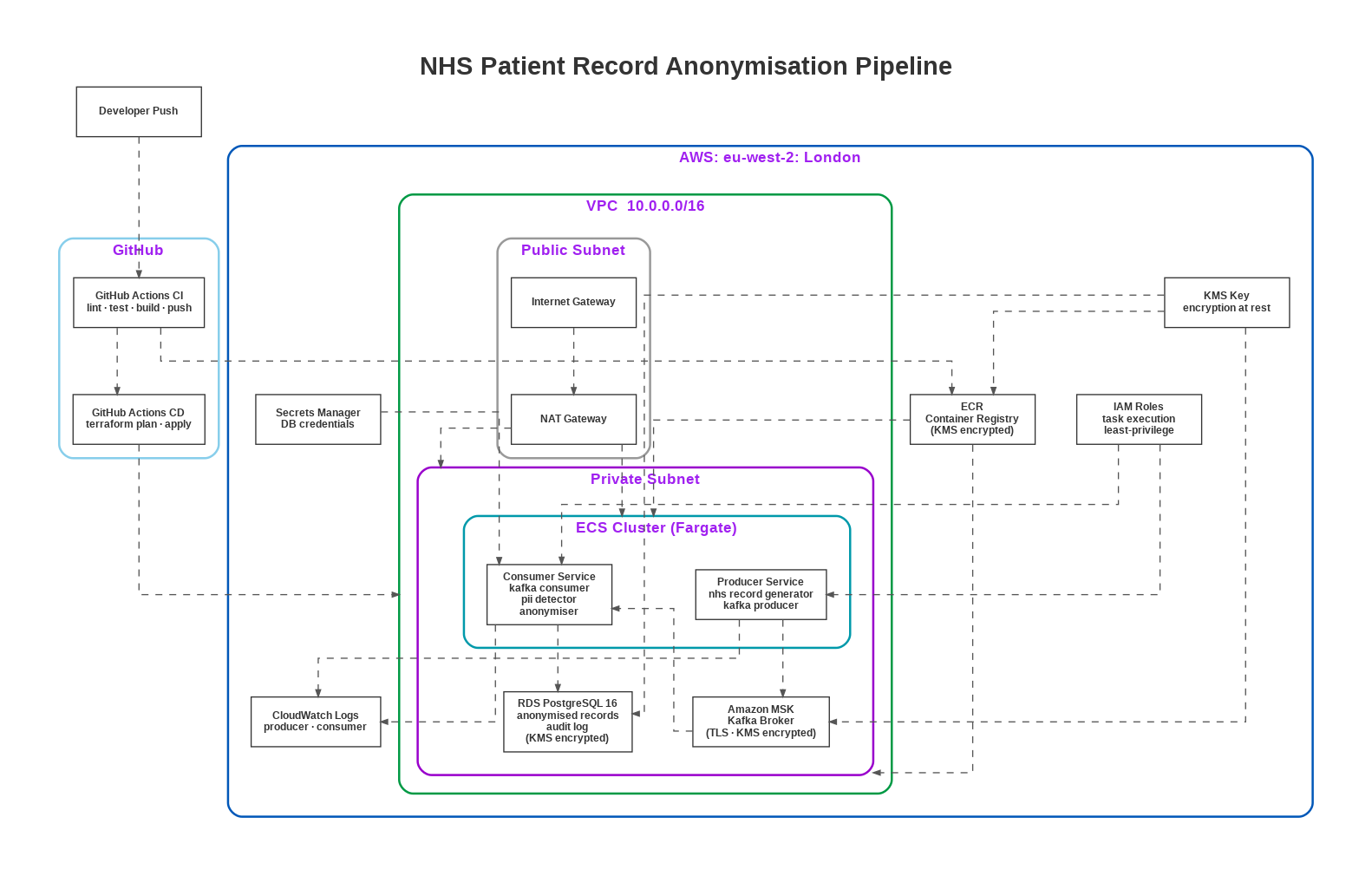
For the sake of visual clarity and to avoid an over-crowded diagram that is unhelpful, this diagram accurately represents
about 90% of the architecture. The core data flow of:
Developer Push -> GitHub Actions -> ECR -> ECS (Private Subnet) -> MSK -> Consumer/Anonymiser -> RDS
is fully shown. The remaining 10% constituting detail-level omissions from the diagram do not misrepresent the system.
It is presented tabulated here:
| Not Shown | Detail |
|---|---|
| DLQ | The dead-letter queue MSK topic (patient-records-dlq) and the DLQ table in RDS are core to the design but absent from the diagram |
| Two consumer replicas | The diagram shows one Consumer Service box - the actual deployment runs x2 replicas |
| MSK has 2 brokers | The diagram shows a single MSK box - in reality it is a 2-broker, multi-AZ cluster (kafka.m5.large × 2) |
| Secrets Manager scope | The diagram labels it "DB credentials" only - it also holds the PSEUDO_SECRET (HMAC key) which is equally critical |
| KMS scope | Shown only on RDS and ECR - KMS also encrypts MSK storage, Secrets Manager values, and CloudWatch logs |
| No health endpoints | /health/live and /health/ready HTTP endpoints on each ECS task are not represented |
Software and Cloud Engineering Trade-offs
1. Kafka (MSK) over SQS or a simpler queue
NHS record ingestion is bursty and high-volume. Kafka's consumer group model enables horizontal scaling of the processing
layer without reprocessing records, and its log retention enables replay for audit and incident investigation - both
essential in a regulated healthcare environment. SQS does not support replay.
2. Pseudonymisation as the default strategy over full redaction
Pseudonymisation preserves referential integrity - the same patient maps to the same HMAC-SHA256 token across all records,
enabling longitudinal cohort analysis. Full redaction destroys this relationship entirely. The strategy is configurable via
environment variable, allowing operators to switch to full redaction for contexts where linkage is not required.
3. ECS Fargate over Lambda
The consumer runs a continuous poll loop - a long-lived, stateful process. Lambda's stateless, time-bounded execution model
is a poor fit for Kafka consumer group membership and offset management. ECS Fargate provides persistent, scalable container
execution without EC2 management overhead.
4. Terraform over console or CDK (Cloud Development Kit)
Every infrastructure component is version-controlled, reviewable, and reproducible. Terraform is a precise, executable
specification of cloud architecture - more reliable and auditable than click-ops, and more portable than CDK which ties
infrastructure code to a single language ecosystem.
Cost Optimisations
This pipeline was fully deployed to AWS and then decommissioned via terraform destroy after successful implementation and
evidence capture - a deliberate FinOps decision.
| Resource | Cost |
|---|---|
| MSK kafka.m5.large × 2 brokers (48 hrs) | ~ $9.22 |
| RDS db.t3.micro PostgreSQL (48 hrs) | ~ $0.86 |
| ECS Fargate tasks (48 hrs) | ~ $1.50 |
| ECR storage | ~ $0.10 |
| Total one-time deployment cost | ≈ $11.70 |
| Ongoing running cost | $0.00 |
The repository, documentation, and architecture diagrams are the portfolio artifact. The design is production-ready and scales to enterprise NHS deployment under standard FinOps governance - but incurs zero persistent cloud spend as a proof of concept.
With access to enterprise budget, I would have more options to be more innovative to build and provision better, cost-effective infrastructure and orchestrated pipelines.
Technical Details
Presented here is a summary - for full technical details please see my GitHub Repo.
The pipeline runs entirely within a private AWS VPC. A Kafka Producer (ECS Fargate) generates synthetic NHS patient records and
publishes them to an Amazon MSK topic. A Kafka Consumer (ECS Fargate, 2 replicas) polls the raw topic, applies the anonymisation
engine, and writes clean records to both an anonymised MSK topic and a PostgreSQL RDS database. Failed records are routed to a
dead-letter queue. All infrastructure is provisioned with Terraform and deployed via GitHub Actions CI/CD.
Although free-text clinical notes are processed for PII using regex pattern matching in this v1 implementation, the pipeline is however
architected for spaCy / medspaCy NER integration - SPACY_MODEL, CONFIDENCE_THRESHOLD, and a full ENTITIES_TO_REDACT
entity list are already configured in config/settings.py - making NLP-based detection a straightforward next step rather than a redesign.
Stack:
Python 3.11 · GitHub Actions · Terraform · Amazon MSK (Kafka) · ECS Fargate · RDS PostgreSQL · ECR · KMS · Secrets Manager · CloudWatch
Anonymisation Engine
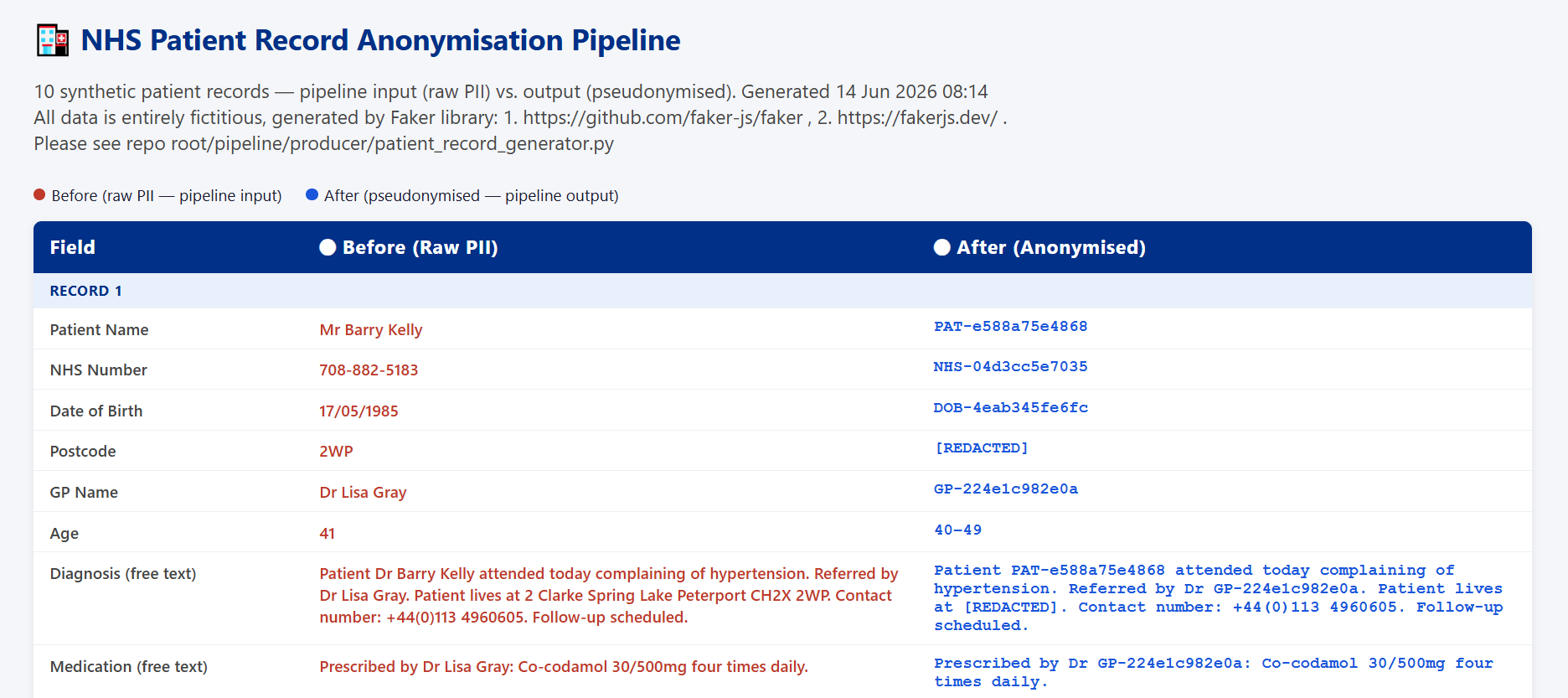
Two pluggable strategies selected via the ANONYMISATION_STRATEGY environment variable:
• Pseudonymisation - deterministic HMAC-SHA256 token replacement per field type (PAT-, NHS-, DOB-, TEL-
prefixed tokens). Same input always produces the same token within a deployment, preserving referential integrity for research.
• Redaction - full [REDACTED] replacement for all PII fields, with additional regex scanning of free-text clinical notes
for names, phone numbers, and email addresses.
Reliability
Manual offset commits (enable_auto_commit=False) - offsets are committed only after successful downstream write,
preventing data loss on consumer failure. Failed records are routed to a dead-letter queue topic and persisted to a
dedicated DLQ database table with full error context for inspection and reprocessing.
Compliance
GDPR Articles 5, 17, 25, and 30 are addressed by design: anonymisation is mandatory in the pipeline path, raw PII never
reaches analytical storage, anonymisation strategy and version are stamped on every output record, and pseudonymisation
key rotation (via PSEUDO_SECRET replacement) invalidates all tokens to satisfy the right to erasure.
Security Posture
Post-deployment security audit identified and documented three findings (ECR tag mutability, local Terraform state, open MSK
plaintext ports) with full root cause analysis and remediation steps. None resulted in exposure of real patient data - the
pipeline operated entirely on synthetic records. Full details in Project GitHub Repo's SECURITY.md.
Testing
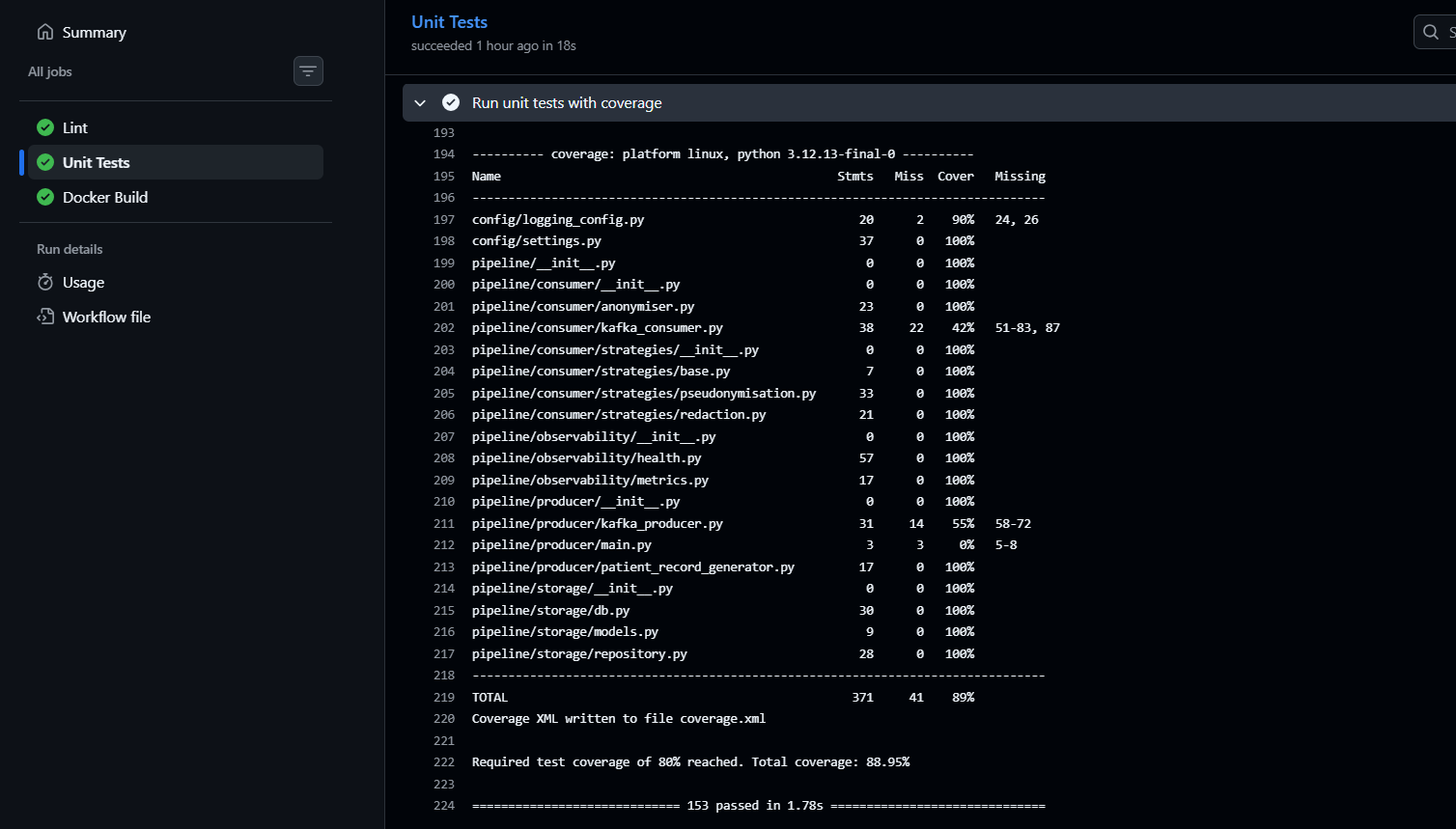
153 unit tests · 89% coverage · pytest · flake8 · black · fully automated in GitHub Actions on every push.
Infrastructure
Terraform-managed: VPC, private subnets, NAT Gateway, MSK (2-broker, multi-AZ, TLS), RDS PostgreSQL 16, ECS Fargate
(producer and consumer services), ECR, KMS (single key encrypts RDS, MSK, Secrets Manager, ECR, CloudWatch), Secrets Manager,
CloudWatch (30-day log retention). All deployed to eu-west-2 (London) - the required region for NHS workloads under
UK data residency requirements.
✨ Coda
This pipeline is designed for teams who need to share clinical data for analytics or research purposes without exposing personally identifiable information (PII).Key capabilities:
- Version 1 generates synthetic NHS patient records (producer)
- Consumes records from Kafka in real time (consumer)
- Applies pluggable anonymisation strategies (pseudonymisation / redaction)
- Persists anonymised records to PostgreSQL with full audit trail
- Routes failed records to a dead letter queue (DLQ)
- Fully containerised with Docker Compose for local development
- CI/CD via GitHub Actions (lint → test → Docker build → push)
🏆 Milestones
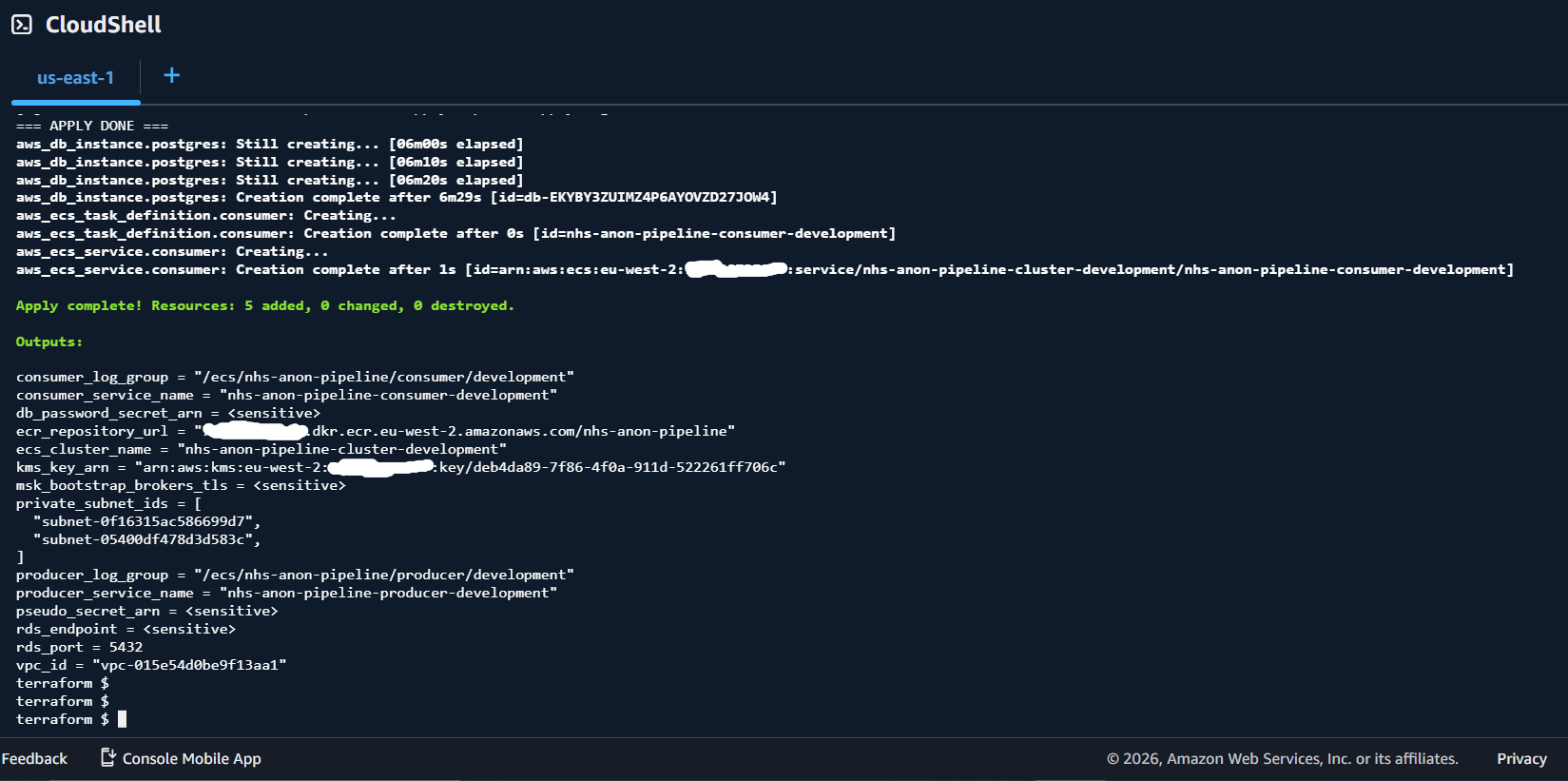
For full list of milestones and screenshots please see GitHub Repo README.1. Fully Deployed AWS Infrastructure:
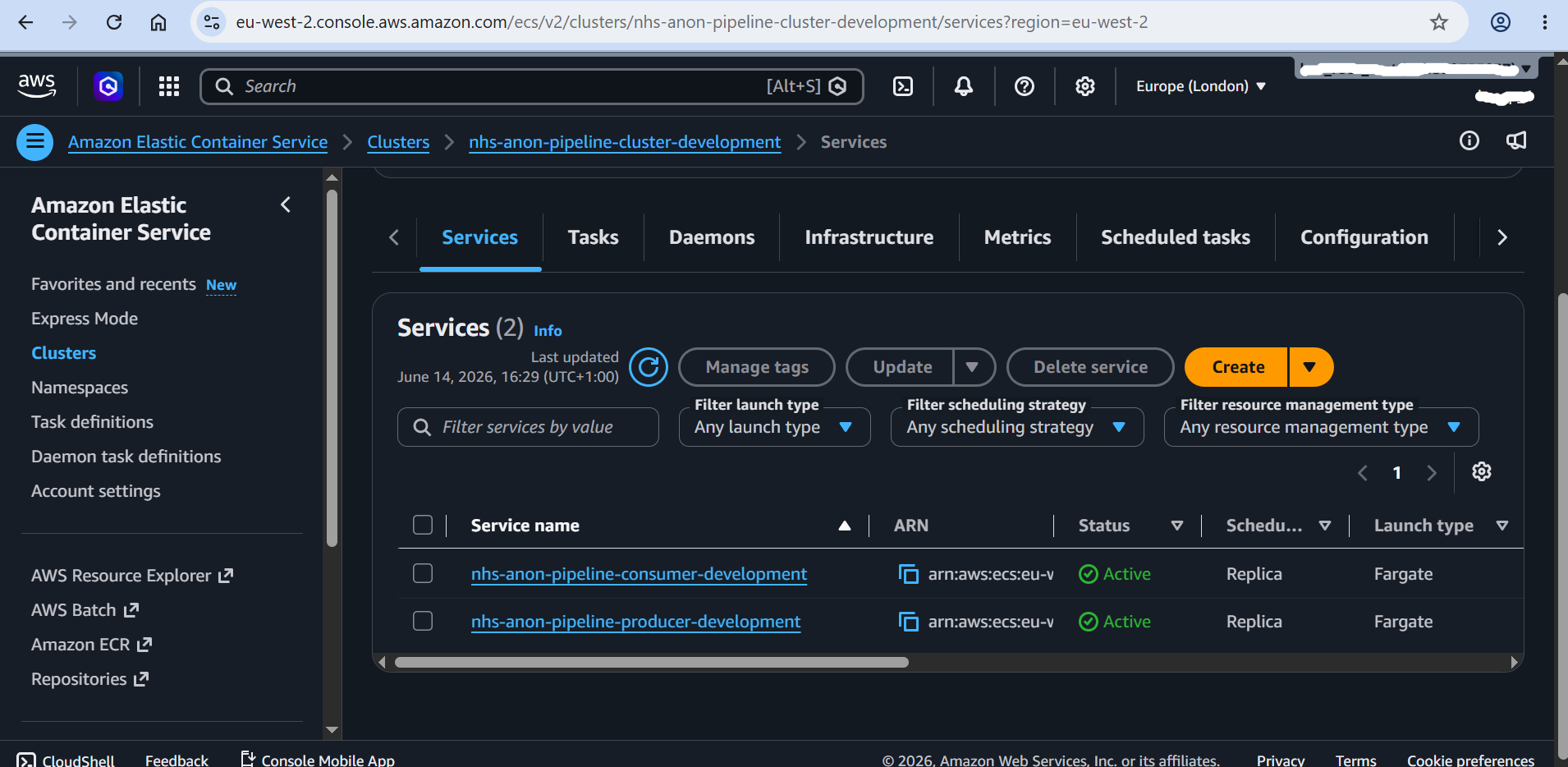
2. Elastic Container Cluster Services:
3. All 153 Unit Tests Passed with 89% Coverage:
4. Sample Patient Record Pre and Post Pipeline:
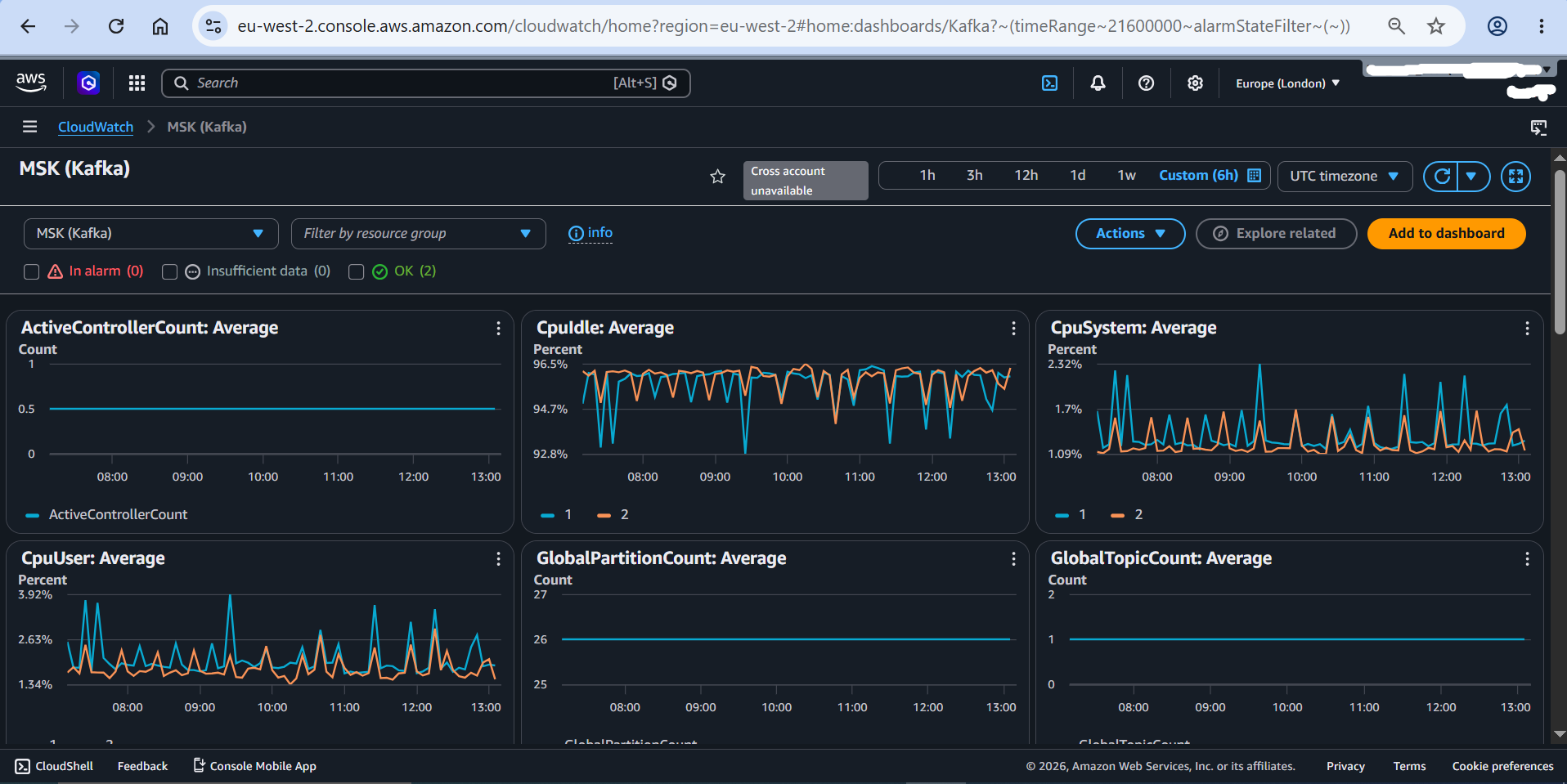
5. CloudWatch Monitoring - MSK Kafka: